Record Breaking ACL 2025 Crowns Four Game-Changing Papers on Speed, Fairness & Safety for Next-Gen LLMs and Beyond
-

Global NLP Community Converges on Vienna for a Record-Breaking 63rd Annual Meeting
Hardware breakthroughs, societal guardrails & time-tested classics.
Below you’ll find expanded snapshots of every major award announced in Vienna, enriched with quick-read insights and primary-source links.Spotlight on the Four Best Papers
Theme Key Idea One-Line Impact Paper & Lead Labs Efficiency Native Sparse Attention (NSA) splits keys/values into Compress · Select · Slide branches with CUDA-level kernels. Long-context LLMs run at full-attention quality but >2× faster on A100s. DeepSeek × PKU × UW — Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention Safety / Alignment Elasticity—pre-training inertia that pulls finetuned weights back to the original distribution. Deep alignment may require pre-training-scale compute, not “cheap” post-training tweaks. Peking U. (Yaodong Yang) — Language Models Resist Alignment: Evidence from Data Compression Fairness “Difference awareness” benchmark (8 scenarios · 16 k Qs) tests when group-specific treatment is desirable. Shows “color-blind” debiasing can backfire; fairness is multidimensional. Stanford × Cornell Tech — Fairness through Difference Awareness Human-like Reasoning LLMs sample responses via descriptive (statistical) and prescriptive (normative) heuristics. Explains subtle biases in health, econ outputs; informs policy audits. CISPA × Microsoft × TCS — A Theory of Response Sampling in LLMs Why They Matter
- Cloud-cost pressure: NSA-style sparsity will be irresistible to any org paying by GPU-hour.
- Regulatory urgency: Elasticity + sampling bias suggest upcoming EU/US safety rules must probe training provenance, not just inference behavior.
- Benchmark reboot: Difference-aware fairness raises the bar for North-American policy datasets.
Beyond the Best: Key Awards

Award Winner(s) Take-Away Best Social-Impact Papers 2 papers Generative AI plagiarism detection · Global hate-speech “day-in-life” dataset. Best Resource Papers 3 papers Multilingual synthetic speech (IndicSynth), canine phonetic alphabet, 1,000 + LM “cartography.” Best Theme Papers 3 papers MaCP micro-finetuning (few KiB params), Meta-rater multidim data curation, SubLIME 80 – 99 % cheaper eval. Outstanding Papers (26) Zipf law reformulations → Token recycling Shows breadth: theory, safety, hardware, evaluation, and even dog phonetics. Best Demo OLMoTrace (AI2) Real-time trace-back of any LLM output to trillions of training tokens—auditability meets UX. TACL Best Weakly-supervised CCG instruction following · Short-story summarization with authors in-the-loop Rethinks grounding & human alignment at smaller scales. Time-Test-of-Time (25 y / 10 y) SRL automatic labeling · Global & local NMT attention Underlines longevity of semantic frames & dot-product attention. Lifetime Achievement Kathy McKeown (Columbia) 43 y pioneering NLG, summarization, and mentoring. Distinguished Service Julia B. Hirschberg (Columbia) 35 y of ACL & Computational Linguistics leadership.
1 · Best Social-Impact Papers
Paper Authors & Affiliations Why It Matters All That Glitters Is Not Novel: Plagiarism in AI-Generated Research Tarun Gupta, Danish Pruthi (CMU) 24 % of 50 “autonomously generated” drafts were near-copy paraphrases that evade detectors—spotlighting plagiarism forensics in autonomous science. HateDay: A Day-Long, Multilingual Twitter Snapshot Manuel Tonneau et al. (Oxford Internet Institute) Eight-language dataset shows real-world hate-speech prevalence is far higher—and model accuracy far lower—outside English.
2 · Best Resource Papers
Dataset / Tool Highlights IndicSynth 2.8 k h of synthetic speech covering 13 low-resource Indian languages; unlocks TTS + ASR research for Bhojpuri, Maithili, Konkani, and more. Canine Phonetic Alphabet Algorithmic inventory of dog phonemes from 9 k recordings—opens the door to cross-species speech NLP. LM Cartography (Log-Likelihood Vector) Embeds 1,000 + language models in a shared vector space; Euclidean distance ≈ KL-divergence—enables taxonomy & drift analysis at linear cost.
3 · Best Theme Papers
Paper One-Sentence Take-Away MaCP: Minimal yet Mighty Adaptation via Hierarchical Cosine Projection JPEG-style cosine pruning lets you fine-tune a 7 B-param LLM with <256 kB of learnable weights—SOTA on NLU + multimodal tasks. Meta-rater: Multi-Dimensional Data Selection Blends 25 quality metrics into four axes—Professionalism, Readability, Reasoning, Cleanliness—cutting pre-train tokens 50 % with +3 % downstream gains. SubLIME: Rank-Aware Subset Evaluation Predicts Spearman ρ to keep ≤20 % of any benchmark while preserving leaderboard order (ρ > 0.9); saves up to 99 % eval FLOPs. 
4 · Outstanding Papers (26)
-
A New Formulation of Zipf's Meaning-Frequency Law through Contextual Diversity.
-
All That Glitters is Not Novel: Plagiarism in Al Generated Research.
-
Between Circuits and Chomsky: Pre-pretraining on Formal Languages Imparts Linguistic Biases.
-
Beyond N-Grams: Rethinking Evaluation Metrics and Strategies for Multilingual Abstractive Summarization
-
Bridging the Language Gaps in Large Language Modeis with inference-Time Cross-Lingual Intervention.
-
Byte Latent Transformer: Patches Scale Better Than Tokens.
-
Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law.
-
From Real to Synthetic: Synthesizing Millions of Diversified and Complicated User Instructions with Attributed Grounding.
-
HALoGEN: Fantastic tiM Hallucinations and Where to Find Them,
-
HateDay: Insights from a Global Hate Speech Dataset Representative of a Day on Twitter.
-
IoT: Embedding Standardization Method Towards Zero Modality Gap.
-
IndicSynth: A Large-Scale Multilingual Synthetic Speech Dataset for Low-Resource Indian Languages.
-
LaTIM: Measuring Latent Token-to-Token Interactions in Mamba Models.
-
Llama See, Llama Do: A Mechanistic Perspective on Contextual Entrainment and Distraction in LLMs.
-
LLMs know their vulnerabilities: Uncover Safety Gaps through Natural Distribution Shifts.
-
Mapping 1,0o0+ Language Models via the Log-Likelihood Vector.
-
MiniLongBench: The Low-cost Long Context Understanding Benchmark for Large Language Models.
-
PARME: Parallel Corpora for Low-Resourced Middle Eastern Languages.
-
Past Meets Present: Creating Historical Analogy with Large Language Models.
-
Pre3: Enabling Deterministic Pushdown Automata for Faster Structured LLM Generation.
-
Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory.
-
Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability.
-
Toward Automatic Discovery of a Canine Phonetic Alphabet.
-
Towards the Law of Capacity Gap in Distilling Language Models.
-
Tuning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling.
-
Typology-Guided Adaptation for African NLP.
5 · Best Demo
Demo What It Does OLMoTrace (AI2) Real-time trace-back of any model output to its multi-trillion-token training corpus—auditing & copyright checks in seconds.
6 · TACL Best Papers
Paper Core Insight Weakly Supervised Learning of Semantic Parsers for Mapping Instructions to Actions Grounded CCG parser learns from trajectory success signals—birth of modern instruction-following. Reading Subtext: Short-Story Summarization with Writers-in-the-Loop Human authors show GPT-4 & Claude miss implicit motives & timeline jumps >50 % of the time—pushing for creative-content benchmarks.
7 · Time-Test-of-Time Awards
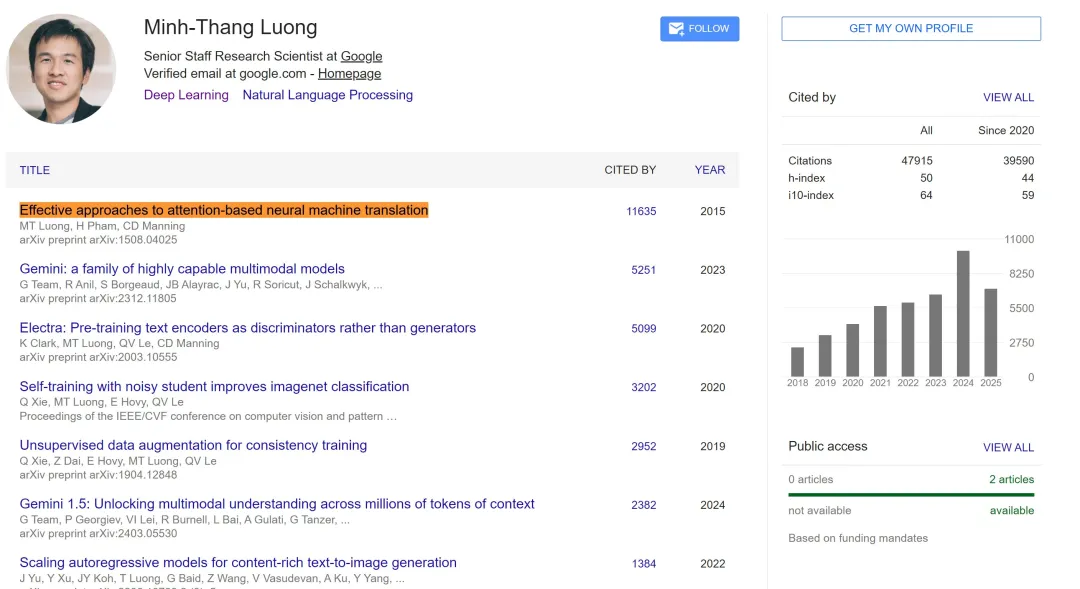
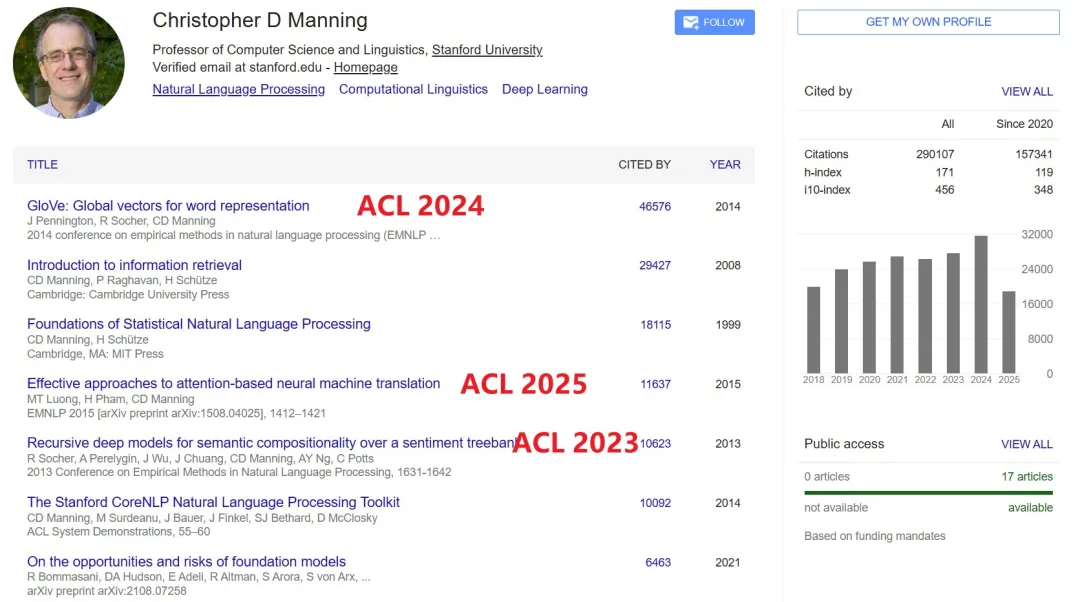
Span Classic Contribution Lasting Impact 25-Year (2000) Automatic Labeling of Semantic Roles (Gildea & Jurafsky) Kick-started SRL; citations > 2.6 k and still foundational for event extraction. 10-Year (2015) Effective Approaches to Attention-Based NMT (Luong et al.) Introduced global vs local attention & dot-product scoring—precursor to today’s Q/K/V transformers. 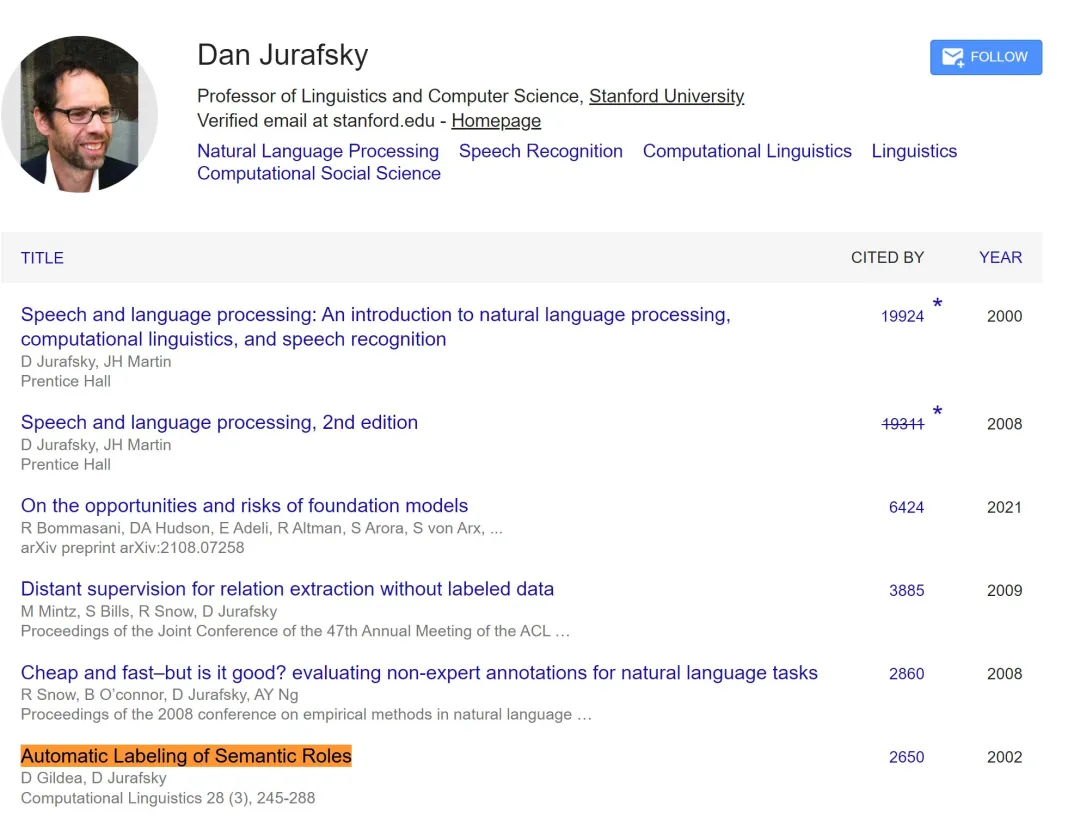
8 · Lifetime & Service Honors
Award Laureate Legacy Lifetime Achievement Kathleen R. McKeown 43 yrs pioneering text generation & multi-doc summarization; founding director, Columbia DSI; mentor to two generations of NLP leaders. Distinguished Service Julia B. Hirschberg 35 yrs steering ACL policy & Computational Linguistics; trail-blazer in prosody & speech dialogue systems. 

What Global Practitioners Should Watch
- The cost curve is bending: Sparse, hardware-aware designs (NSA, KV-eviction, token recycling) will dictate which labs can still train frontier models as GPU prices stay volatile.
- Alignment ≠ Fine-tuning: “Elasticity” reframes safety from a patching problem to a co-training problem—expect a rise in alignment-during-pre-train methods and joint governance.
- Fairness travels badly: Benchmarks rooted in US civil-rights law clash with Asian data realities. Multiregional “difference aware” suites could become the next multilingual GLUE.
- Provenance is product-ready: OLMoTrace & trace-back demos indicate that open-source stacks will soon let enterprises prove where every token came from—key for EU AI Act compliance.
- Author demographics matter: With 51 % first authors from China, conference culture, tutorial topics, and even review guidelines are drifting East. Western labs must collaborate, not compete on size alone.
TL;DR
ACL 2025 broke every record—but more importantly, it set the agenda: build LLMs that are faster (DeepSeek), fairer (Stanford/Cornell), safer (Peking U.), and more human-aware (CISPA). The future of NLP will be judged not just by scale, but by how efficiently and responsibly that scale is used.