🔥 ICML 2025 Review Results are Coming! Fair or a Total Disaster? 🤯

-
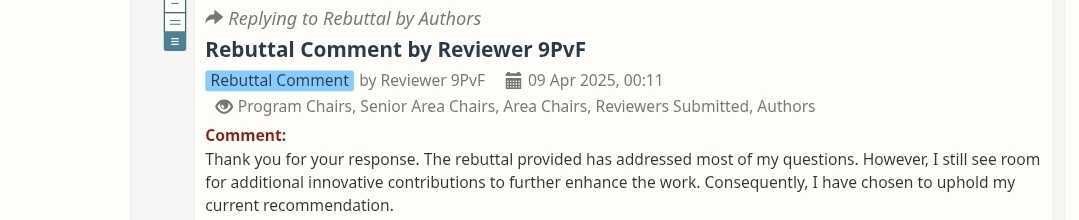
When “You answered my questions” somehow translates to “Still a weak reject.”
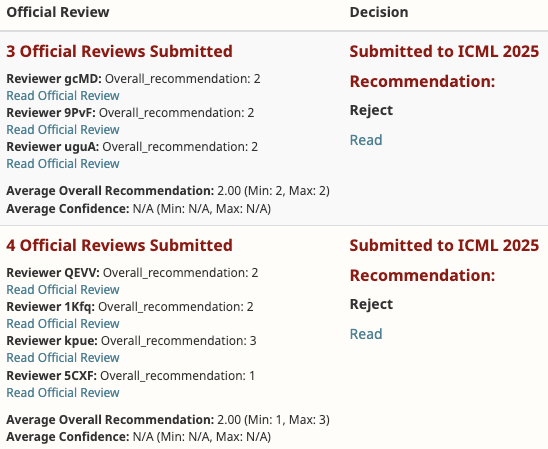
Attached is a classic case of “Thanks, but no thanks” review logic
Even when your method avoids combinatorial explosion and enables inference-time tuning… innovation apparently just isn’t innovative enough?
Peer review or peer roulette?


-
Just wanted to casually share a couple of ICML rebuttal stories I came across recently. If you're going through the process too, maybe these resonate.
Case 1: Maxwell - When the System Feels Broken
Maxwell submitted three papers this year. Got ten reviewers in total. So far? All ten acknowledged the rebuttal, but zero replied, zero changed scores. Even worse, he says at least two reviews look like they were written entirely by ChatGPT. He tried reaching out to the Area Chair, but got radio silence.
He also reflected on some bigger issues with ML conference peer review in general. In his words, the bar is too low. There's no desk reject phase like in journals, and papers can be endlessly recycled, so a lot of half-baked submissions flood in hoping to hit the jackpot.
Maxwell suggested a few radical ideas:
- Fix the number of accepted papers per year (e.g., cap it at 2500).
- Only the top 5000 submissions (or 50% of total) go to actual review.
- Introduce a yearly desk reject quota per author. If you get desk rejected 6 times, you're banned from submitting to the top conferences for that year.
Yeah, this would definitely stir things up and reduce the number of papers, but he argues it's the only way to fix quality and reviewer burnout. Tough love?

Case 2: 神仙 - Reviewer Missed the Point
神仙 had a different kind of frustration. His paper proposed a method to accelerate a system under a given scenario (let’s call it scenario A). But multiple reviewers fixated on why A was designed the way it was, not on the actual method.
This was super frustrating since A was just a fixed example, not the subject of the paper. So he’s planning to carefully explain this misunderstanding in the rebuttal and hopes it will help increase the score.
He also noted a pattern: reviewers who gave low scores are more responsive in rebuttal, while those who gave high scores often don't even acknowledge. Anyone else notice this trend?
Some of my thoughts
One story points to deeper structural problems in the review system. The other is just classic misalignment between what authors write and what reviewers pick up on.
Whether you're running into AI-generated reviews, silent ACs, or just misunderstood contributions, you're not alone.
Curious to hear if others had similar experiences. Rebuttal season is rough.
Good luck everyone.
-
I hereby post the historical acceptance rate of ICML:
Conference Acceptance Rate and Stats ICML'14 15.0% (Cycle I), 22.0% (Cycle II) ICML'15 26.0% (270/1037) ICML'16 24.0% (322/?) ICML'17 25.9% (434/1676) ICML'18 25.1% (621/2473) ICML'19 22.6% (773/3424) ICML'20 21.8% (1088/4990) ICML'21 21.5% (1184/5513) (166 long talks, 1018 short talks) ICML'22 21.9% (1235/5630) (118 long talks, 1117 short talks) ICML'23 27.9% (1827/6538) (158 live orals, 1669 virtual orals with posters) ICML'24 27.5% (2610/9473) (144 orals, 191 spotlights and 2275 posters) -
From official email: "This year, we received 12,107 submissions (not including desk-rejected papers), which is an increase of 28% from last year. From these submissions, we have accepted 3,260, giving an acceptance rate of 26.9%. Only 313 were designated as "spotlight posters" -- representing the top 2.6% of all submissions. The spotlights represent the submissions most highly-recommended by the program committee. Decisions about oral presentations have not been finalized, but will be done in the coming weeks."
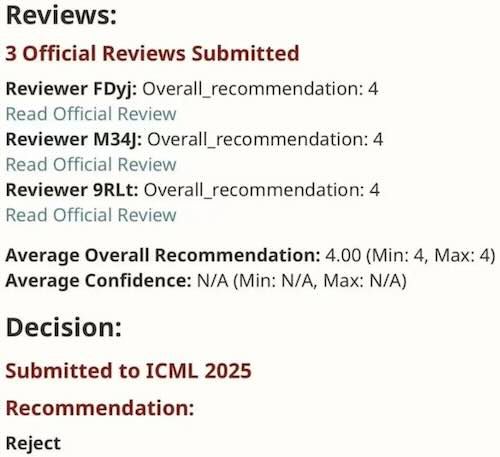
At the same time some initial data points, where paper with scores 1123 got accepted??

-
2 rejects