"Your review may have been co-authored by AI." – ICLR 2025
-
"Your review may have been co-authored by AI." – ICLR 2025
Peer review in computer science conferences has long been under pressure — volume grows, reviewer fatigue increases, and quality sometimes suffers. But ICLR 2025 just ran a bold experiment to fix that. The idea? Let AI critique the critics.
This post walks through the technical design and impact of the Review Feedback Agent, a large-scale deployment of LLM-generated feedback on over 20,000 reviews, as documented in a research paper available on arXiv.
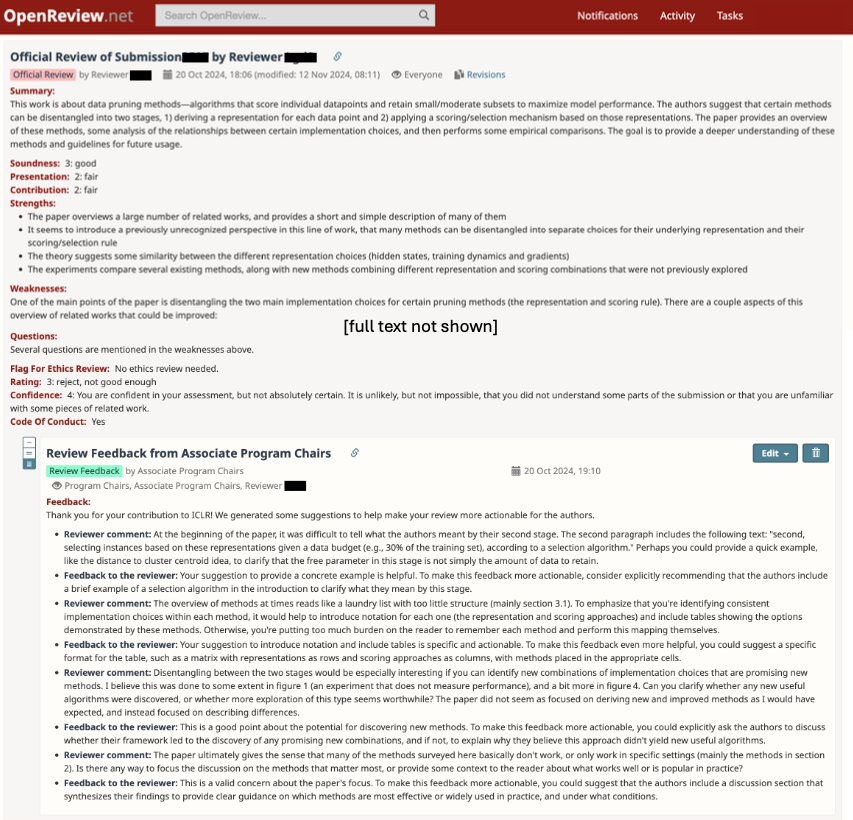
An example of feedback posted to a review on the OpenReview website (with consent from the reviewer). Feedback is only visible to the reviewer and the ICLR program chairs and was posted roughly one hour after the initial review was submitted.
🧠 The Idea: LLMs to Review the Reviewers
The team from Stanford, UCLA, Columbia, Google Research, and others created a multi-agent system called Review Feedback Agent. Its job was simple but ambitious: detect low-quality peer review comments and gently nudge reviewers to improve them.
It targeted three issues:
- Vague or generic comments ("not novel", "needs more experiments")
- Misunderstandings of the paper (e.g., missing that a figure answers a concern)
- Unprofessional language ("the authors clearly have no idea what they're doing")
Each problematic comment would receive personalized, AI-generated feedback, but only if it passed a suite of automated quality and reliability checks.
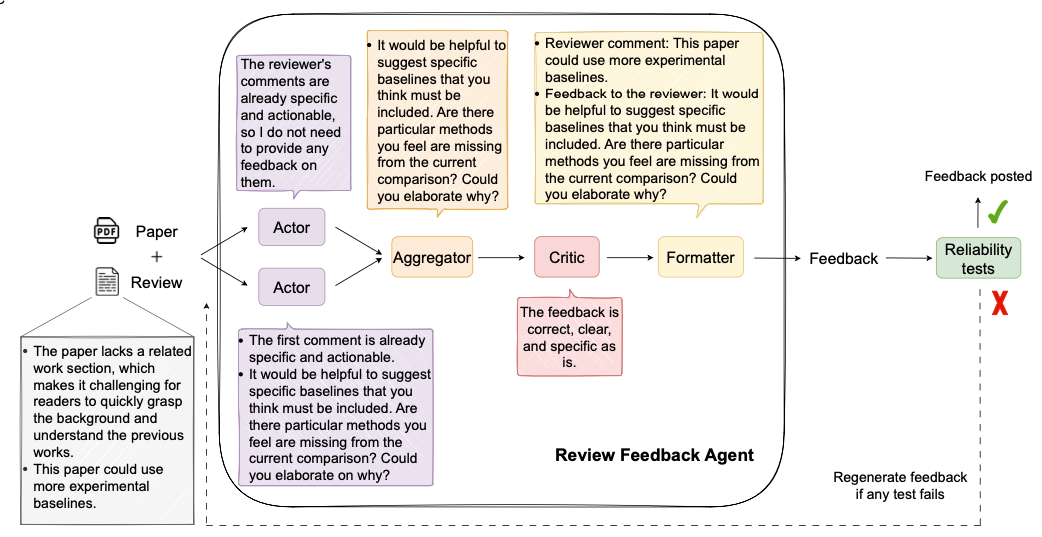
 ️ How It Worked: Behind the Scenes
️ How It Worked: Behind the ScenesThe Review Feedback Agent used a pipeline of five LLMs:
- Actors (2x): Generate initial feedback proposals
- Aggregator: Merge and deduplicate
- Critic: Validate for clarity, utility, tone
- Formatter: Structure the feedback
These models worked together to produce helpful and non-intrusive suggestions. If any step failed reliability tests (e.g., vague feedback or unnecessary praise), the system regenerated or discarded the result.
Only feedback that passed all guardrails was posted back to the reviewer via OpenReview, approximately one hour after they submitted their review.
 The Experiment Setup
The Experiment SetupThe study was a randomized controlled trial over the ICLR 2025 review period.
- ICLR 2025 received 11,603 submissions and 44,831 reviews
- Each paper was assigned to 3–4 reviewers
- ~50% of reviews were randomly selected to receive AI feedback
- Feedback was posted as a private comment, visible only to the reviewer and the PC
- Reviewers were not required to change anything
This created a natural experiment to test: does feedback improve reviews?
 Key Results
Key Results Reviewers Took Feedback Seriously
Reviewers Took Feedback Seriously- 26.6% of reviewers who received feedback updated their reviews
- Of those, 89% incorporated at least one feedback item
- In total, 12,222 suggestions were adopted into updated reviews
On average, review length increased by 80 words for updated reviews.
 Better Reviews, Better Discussions
Better Reviews, Better Discussions- Human evaluators preferred updated reviews in 89% of blind comparisons
- Feedback group reviews led to:
- 6% longer author rebuttals
- 5.5% longer reviewer replies
- More reviewers changed their scores after the rebuttal
These findings suggest that AI feedback didn't just improve the initial review quality, it made author–reviewer discussions more thoughtful and substantive. I personally would like to put a question mark on the "longer" criteria their used
")
 What Kind of Feedback Was Given?
What Kind of Feedback Was Given?A clustering analysis of ~70,000 feedback items revealed:
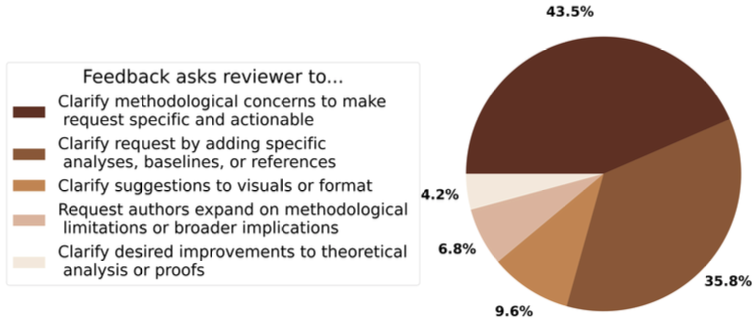
- 43.5%: Asked reviewers to clarify vague methodological concerns
- 35.8%: Encouraged adding specifics like baselines or references
- Other clusters focused on visuals, theoretical clarity, or broader implications
Interestingly, feedback about content misunderstandings was rarer, because the system was designed to focus on the side of caution to avoid hallucinating explanations not supported by the paper text.
🧪 Lessons for the Peer Review Community
This ICLR experiment marks the first large-scale deployment of LLMs to assist peer reviewers, and it was rigorously evaluated. Some takeaways for the research community:
- AI can help: when designed with care, LLMs can improve review quality and engagement
- Guardrails matter: automated reliability tests are critical to prevent bad suggestions
- Human agency is key: reviewers retained full control and could ignore feedback
- It scales: each review cost ~$0.50 and took ~1 minute to process
 Limitations & Future Work
Limitations & Future Work- Feedback didn’t significantly impact acceptance rates (32.3% vs. 30.8%)
- The system didn’t address review novelty, expertise matching, or bias
- Future versions may benefit from reasoning LLMs and toxicity benchmarks
As AI/ML conferences wrestle with volume and reviewer overload, this experiment opens the door to LLMs as review assistants: not to replace reviewers, but to support them.
 Further Reading
Further Reading
What do you think? Should NeurIPS or ACL try this next? Register (verified or anonymous) to Join the Discussion

