🤖The AI-for-Science Hype, Peer Review Failures, and the Path Forward
-
Last week I read an eye-opening essay titled "I got fooled by AI-for-science hype—here’s what it taught me" by physicist Nick McGreivy. It is an honest account of how high expectations for AI in physics ran headfirst into brittle models, weak baselines, and, most critically, a scientific publishing system that rarely reports when AI fails.
This story isn’t just about physics; it’s a mirror reflecting systemic issues in peer-reviewed AI research, especially in computer science conferences like NeurIPS, ICML, and ICLR. Let’s talk about why this is happening, and where we might go from here.
 From Plasma Physics to Peer Review Pitfalls
From Plasma Physics to Peer Review PitfallsNick's journey started with high hopes for using machine learning to solve partial differential equations (PDEs). He tried PINNs (Physics-Informed Neural Networks), inspired by their 14,000 citations and glowing papers. But he quickly found they didn’t work on even modestly different PDEs.
“Eventually, I realized that the original PINN paper had selectively reported successes and omitted failures.”
And it wasn’t just PINNs. In a review of 76 ML-for-PDE papers:
- 79% used weak baselines to claim superiority.
- Very few reported negative results.
- The most hyped outcomes were the most misleading.
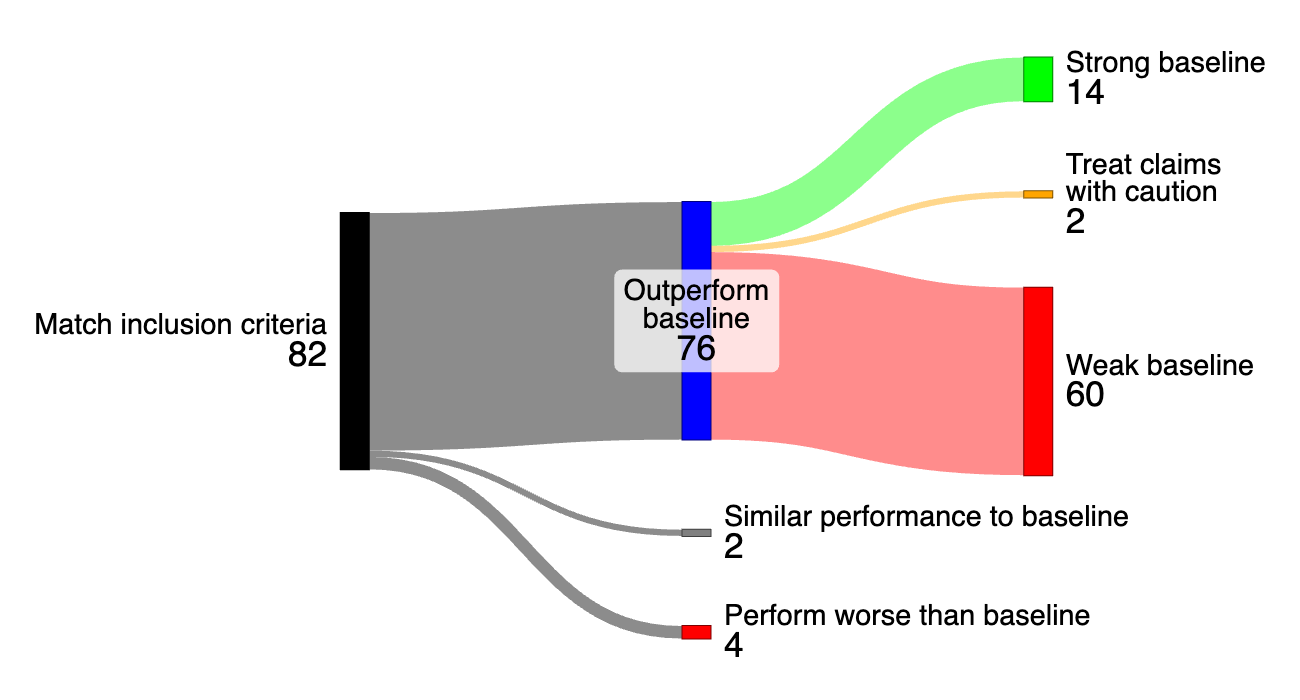
60 out of 76 AI-for-PDE papers used weak baselines. Strong baseline comparisons drastically reduced the performance claims.
🧪 This Sounds Familiar... Hello, Computer Science
These patterns, selective reporting, weak baselines, cherry-picking, and data leakage, aren’t just physics problems. They’re endemic in the AI research culture, particularly in CS conferences:
1. Survivorship Bias
Conferences reward “novel and positive results.” Negative results? Not welcome. This distorts the field, making AI look more capable than it is.
2. Reviewer Incentives
Reviewers are often working on similar topics. Accepting “hyped” papers may boost their own citation networks, leading to conflicts of interest.
3. Benchmark Gaming
How many papers claim state-of-the-art by subtly tweaking test splits or cherry-picking metrics? Quite a few. The culture of leaderboard chasing dilutes scientific rigor.
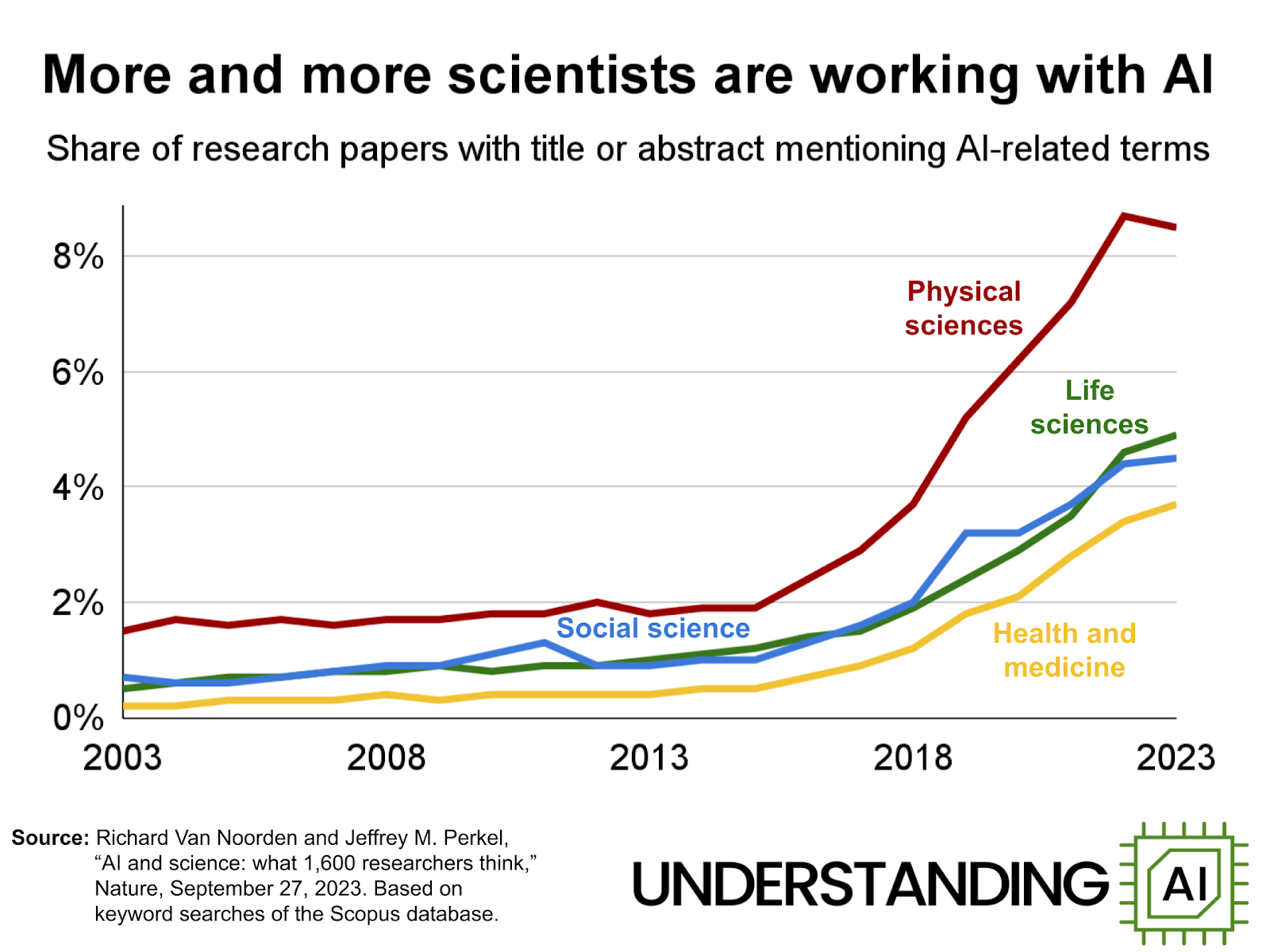
The rise in AI mentions across disciplines: from 2% in 2015 to nearly 8% in 2022—raises questions about depth vs hype.
 My Take: Science Is Not a Startup Pitch
My Take: Science Is Not a Startup PitchMcGreivy rightly points out:
“AI adoption is exploding among scientists less because it benefits science and more because it benefits the scientists themselves.”
Just as a startup might inflate a TAM (Total Addressable Market) to impress VCs, many researchers unintentionally inflate their AI’s potential to impress reviewers and get published. The difference? In science, these distortions can misguide entire research agendas.
 What Needs to Change
What Needs to ChangeLet’s be constructive. Here’s what I believe we need in CS/AI peer review:
 Stronger Baselines and Ablations
Stronger Baselines and AblationsPapers should compare against state-of-the-art, not strawmen. Ablation studies should be mandatory for claims about novel components.
Negative Results TrackNeurIPS experimented with this before. We need a permanent home for negative or inconclusive findings.
Reviewer EducationProvide checklists to reviewers: Have strong baselines been used? Are the gains statistically significant? Is there a reproducibility artifact?
Independent BenchmarksThe NLP community has benefited from shared tasks and datasets (GLUE, SuperGLUE). We need more of these in other domains.
 Finally
FinallyThe article is a refreshing reminder: Just because something works with AI doesn’t mean it’s better. And just because it’s published doesn’t mean it’s trustworthy.
Let’s aim for a culture where rigor beats razzle-dazzle, and where peer review serves truth, not trendiness.
Would love to hear your thoughts. Have you seen similar issues in your domain?
Images from the article "I got fooled by AI-for-science hype — here’s what it taught me" by Nick McGreivy.