🔍 GPT-5 for Paper Review? CSPaper Benchmark Results May Surprise You! 🤖📊
-

With the release of GPT-5, the AI research community has been buzzing — some praising its brilliance, others lamenting its inconsistency. Just take a glance at the mixed feedback across channels like this sharing and discussion or this discussion on prompt engineering. Is GPT-5 really better, or does it just need the right prompt?

At CSPaper Review, we let data do the talking.
🧪 Benchmarking GPT-5: How Does It Perform?
We evaluated GPT-5 on our small (for now) scale benchmark consisting of 100 research papers across top-tier CS conferences. Each paper has ground-truth overall review scores. Our comparison metric? Mean Absolute Error (MAE) between model prediction and human review scores. Lower is better.
Here's the result:
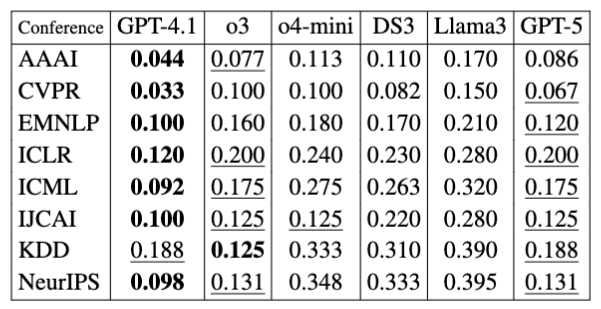
_Note: “DS3” refers to DeepSeek-v3. Bold = best, underlined = second-best.
 Key Observations:
Key Observations:- GPT-5 achieves second-best performance in 7 out of 8 conferences, but is never the best.
- GPT-4.1 consistently ranks among the top, being best in 6 out of 8 benchmarks.
- Lightweight versions like o4-mini lag behind in most cases.
- LLaMA3 and DeepSeek generally trail behind the GPT-family models.
So despite all the hype, GPT-5 is solid but not clearly superior — at least, not without further tuning or prompting.
 But Is GPT-5 More "Verbose"?
But Is GPT-5 More "Verbose"?We also examined each model’s average output length (count of generated words in resulting reviews) — a proxy for verbosity and elaboration in review generation:
Conference GPT-5 GPT-4.1 o3 o4-mini Mean length 12821 11111 8184 8137  Commentary:
Commentary:- GPT-5 generates the longest reviews, by a margin of ~1,700 words over GPT-4.1 and nearly 50% longer than o3/o4-mini.
- This suggests GPT-5 might elaborate more — potentially helpful in nuanced cases, but also possibly more prone to redundancy or hallucination.
 Conclusion: Not Switching... Yet
Conclusion: Not Switching... YetDespite its capabilities, GPT-5 does not yet justify replacing the best performing models in our pipeline. It performs reasonably but does not significantly outperform the current setup in either accuracy or efficiency.
That said, we’re not closing the door. If future prompting strategies or fine-tuning tricks can unlock GPT-5’s full potential on peer review tasks, we might revisit.
Stay tuned for more benchmarks and improvements at CSPaper Review. 🧠

We plan to share these results and more of our learnings on a short research paper soon. For anyone interested, please stay tuned ...