ICLR'25 and ICML'24 Papers Are Strikingly Similar! Netizens Are Furious
-
Originally posted by Zhihu user “灰瞳六分仪” (Huítóng Liùfēnyí) on: March 28, 2025, 16:47
I’d like to point out a paper that I found rather disturbing — I noticed that the ICLR 2025 paper Mixture of Attentions (MoA) is strikingly similar to the ICML 2024 paper GliDe. Let’s first drop the links to both papers:
MoA: https://openreview.net/pdf?id=Rz0kozh3LE
GliDe: https://openreview.net/pdf?id=mk8oRhox2I
To be honest, I initially had no intention of bringing this to Zhihu — after all, allegations of potential academic misconduct are very serious. So I first posted a public comment on OpenReview, politely asking the authors for clarification. But the author’s response and the excuse made in the camera-ready version really infuriated me. So now I’m going to break this down properly.
The Excuse That Made Me Mad
Let’s look at how the authors themselves explained the difference between MoA and GliDe in the camera-ready version:
Du et al. (2024) previously proposed to leverage the KV-cache of some layers of 𝓜_{large}. They do not justify why using the KV-cache instead of the output of each layer, nor how to exactly choose which layer to include as input of 𝓜_{small} However, with our dynamical system point of view, we showed that the KV-cache of all the layers is part of the state. The introduction of LSA allows to exploit it in its whole with a limited number of layers, whereas Du et al. (2024) would need to have the same number of layers in 𝓜_{small} and 𝓜_{large} to fully capture it, resulting in a slow drafting speed.
This explanation claims a “lack of justification” from Du et al. (2024), but…
This Is Just Wrong.
GliDe only used the last layer’s KV cache — and explicitly ran ablation studies to justify this. Check Figure 7 of the GliDe paper if you don’t believe me.
Such a misleading statement raises the question: Were MoA’s authors intentionally trying to confuse readers and obscure the similarity between the two works?
A Side-by-Side Comparison of Core Methods
Let me help the MoA authors do a better comparison between GliDe and MoA. Below are the main method diagrams from both papers:
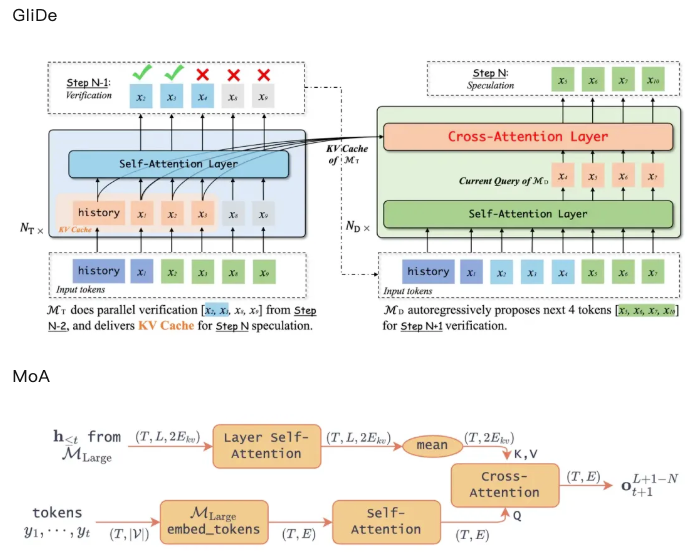
So yeah, the core frameworks are nearly identical. If we’re nitpicking, the difference is:
- GliDe uses only the last layer’s KV cache
- MoA takes the average across all layers’ KV cache
I’ve summarized this comparison in the table below.
Method GliDe (ICML 2024) MoA (ICLR 2025) Core Process Pass input through the target model (large model)'s embedding layer, then generate query via self-attention, and finally compute cross-attention with the target model's KV cache Same as GliDe: embedding → self-attention → compute cross-attention with KV cache from the target model Use of Target Model's KV Cache Only uses the last layer of the target model's KV cache Uses the entire KV cache from all layers of the target model Draft Model Layers 1 layer for 7B/13B models, 2 layers for 33B model 1 layer Citation Issues in MoA: Avoiding GliDe on Purpose?
Despite the similarity, the initial draft of MoA didn’t cite GliDe at all!
 This likely caused the four reviewers and AC to miss the similarity in methodology — which probably explains why MoA scored so highly (6,6,8,8).
This likely caused the four reviewers and AC to miss the similarity in methodology — which probably explains why MoA scored so highly (6,6,8,8).Academic ethics require properly citing related work, especially if the work is highly similar. I’m not going to declare this academic misconduct, but I do believe the authors benefited from this omission.
Side Note: Why Did GliDe Perform Worse Than EAGLE, But MoA Didn't?
I figured this out while working on LongSpec. In my view, GliDe actually has high potential, because the information in hidden states should also exist in the KV cache. I wrote in a previous reading note:
“This paper shares the same idea as EAGLE — both reuse the target model’s knowledge of the prompt. The only difference is: this paper uses the KV cache, while EAGLE uses hidden states. Logically, KV cache should be slightly better.”
According to experts at together.ai, their reproduction results also show that MoA performs slightly better.
So why did GliDe underperform in its paper?
- The original GliDe code had quite a few bugs
 .
. - During MT-Bench evaluation, GliDe only evaluated the first turn — discarding subsequent prompts. The later turns, usually involving error correction, should have contributed significantly to accept rate.
So honestly, the main contribution of MoA is just getting GliDe to work properly.
Conclusion
Based on the above analysis, here’s my personal opinion:
- The core methods of MoA and GliDe are highly similar — with little innovation — this is essentially a duplicate.
- MoA’s authors misrepresented GliDe’s method in their camera-ready version to create the illusion of difference.
- MoA’s draft did not cite GliDe, possibly intentionally — which violates academic norms.
Regrettably, I didn’t discover this paper during the discussion phase, so I missed the opportunity to raise it with reviewers. I later submitted a report to the ICLR program committee — but it went nowhere. In the end, MoA was still accepted to ICLR 2025.

What do you think — does this count as academic misconduct?