🎪 ACL 2025 Reviews Are Out: To Rebut or Flee? The Harsh Reality of NLP’s "Publish or Perish" Circus
-
The Verdict: ACL 2025 Review Scores Decoded
This year’s Overall Assessment (OA) descriptions reveal a brutal hierarchy:
 5.0 "Award-worthy (top 2.5%)"
5.0 "Award-worthy (top 2.5%)" ️ 4.0 "ACL-worthy"
️ 4.0 "ACL-worthy" 3.5 "Borderline Conference"
3.5 "Borderline Conference" 3.0 "Findings-tier" (Translation: "We’ll take it… but hide it in the appendix")
3.0 "Findings-tier" (Translation: "We’ll take it… but hide it in the appendix") 1.0 "Do not resubmit" (a.k.a. "Burn this and start over")
1.0 "Do not resubmit" (a.k.a. "Burn this and start over")
Pro tip: A 3.5+ OA avg likely means main conference; 3.0+ scraps into Findings. Meta-reviewers now hold life-or-death power—one 4.0 can save a 3.0 from oblivion.
Nightmare Fuel: The 6-Reviewer Special
"Some papers got 6 reviewers—likely because emergency reviewers were drafted last-minute. Imagine rebutting 6 conflicting opinions… while praying the meta-reviewer actually reads your response."
Rebuttal strategy:
- 2.0? "Give up." (Odds of salvation: ~0%)
- 2.5? "Worth a shot."
- 3.0? "Fight like hell."
The ARR Meat Grinder Just Got Worse
New changes to the ARR (Academic Rebuttal Rumble):
 5 cycles/year now (April’s cycle vanished; June moved to May).
5 cycles/year now (April’s cycle vanished; June moved to May).- EMNLP’s deadline looms closer — less time to pivot after ACL rejections.
 LLM stampede: *"8,000+ submissions per ARR cycle!
LLM stampede: *"8,000+ submissions per ARR cycle!
"Back in the days, ACL had 3,000 submissions. No Findings, no ARR, no LLM hype-train. Now it’s just a content farm with peer review."
How to Survive the Madness
 Got a 3.0? Pray your meta-reviewer is merciful.
Got a 3.0? Pray your meta-reviewer is merciful.- 🤬 Toxic review? File an "issue" (but expect crickets).
 ARR loophole: "Score low in Feb? Resubmit to May ARR and aim for EMNLP."
ARR loophole: "Score low in Feb? Resubmit to May ARR and aim for EMNLP."
The Big Picture: NLP’s Broken Incentives
- Reviewer fatigue: Emergency reviewers = rushed, clueless feedback.
- LLM monoculture: 90% of papers are "We scaled it bigger" or "Here’s a new benchmark for our 0.2% SOTA."
- Findings graveyard: Where "technically sound but unsexy" papers go to die.
Final thought: "If you’re not gaming the system, the system is gaming you."
Adapted from JOJO极智算法 (2025-03-28)
 Register (verified or anonymous) to share your ACL 2025 horror stories below! Did you rebut or run?
Register (verified or anonymous) to share your ACL 2025 horror stories below! Did you rebut or run? -
My initial scores are OA 2.5/2.5/2
It got raised to OA 2.5/2.5/2.5 ... Well, become a bit better LOL!
Any chance for findings? -
 Some review scores I have seen
Some review scores I have seenStronger or Mid-range Submissions
-
OA: 4/4/4, C : 2/2/2
Concern: Low confidence may hurt chances. -
OA: 4, 4, 2.5, C : 4, 4, 4
Community says likely for Findings. -
OA: 3, 3, 3, C : 5, 4, 4
Possibly borderline for Findings. -
OA Average: 3.38, Excitement: 3.625
Decent shot, though one reviewer gave 2.5. -
OA average: 3.33
Reported as the highest OA seen by one reviewer – suggests bar is low this cycle.
Weaker Submissions
-
OA: 2.5, 2.5, 1.5,
 4, 3, 3
4, 3, 3
Unlikely to be accepted. -
OA: 2, 1.5, 2.5,
4, 4, 4
Most agree no chance for Findings. -
OA: 3, 3, 2.5,
4, 3, 4
Marginal; some optimism for Findings. -
Only two reviews, one with meaningless 1s and vague reasoning
ACs often unresponsive in such cases.
Some guessing from community
Findings Track:
- Informal threshold: OA ≥ 3.0
- Strong confidence and soundness can help borderline cases
Main Conference:
- Informal threshold: OA ≥ 3.5 to 4.0
- Very few reports of OA > 3.5 this cycle
Score Changes During Rebuttal:
- Rare but possible (e.g., 2 → 3)
- No transparency or reasoning shared
Info on review & rebuttal process
- Reviews were released gradually, not all at once
- Emergency reviews still being requested even after deadline
- Author response period extended by 2 days
- Confirmed via ACL 2025 website and ACL Rolling Review
- Meta-reviews and decisions expected April 15
To summarize
- This cycle’s review scores seem low overall
- OA 3.0 is a realistic bar for Findings track
- OA 3.5+ likely needed for Main conference
- First-time submitters often confused by lack of clear guidelines and inconsistent reviewer behavior
-
-
Continued sample scores from zhihu
🟩 Borderline to Promising Scores
-
4 / 3 / 3 (Confidence: 3 / 4 / 4)
Hoping for Main Conference acceptance.
-
4 / 3 / 2.5 (Confidence: 3 / 4 / 4)
Reviewer hinted score could increase after rebuttal.
-
3.5 / 3.5 / 3 (Meta: 3)
For December submission. Ask: is that enough for Findings?
-
3.5 / 3.5 / 2.5 (Confidence: 3 / 3 / 4)
Author in the middle of a tough rebuttal. Main may be ambitious.
-
3.5 / 3 / 2.5
Open question: what's the chance for Findings?
-
3 / 3 / 2.5 (Confidence: 3 / 3 / 3)
Undergraduate author. Aims for Findings. Rebuttal will clarify reproducibility.
-
3.5 / 2.5 / 2.5 (Confidence: 3 / 2 / 4)
Community sees this as borderline.
🟨 Mediocre / Mixed Outcomes
-
2 / 3 / 4
One reviewer bumped the score after 6 minutes (!), but still borderline overall.
-
2 / 2.5 / 4
Rebuttal effort was made, but one reviewer already dropped. Probably withdrawn.
-
2 / 3.5 / 4
Surprisingly higher for a paper the author didn’t expect to succeed.
🟥 Weak or Rejected Outcomes
-
4 / 1.5 / 2 (Confidence: 5 / 3 / 4)
Likely no chance. Community reaction: “Is it time to give up?”
-
3 / 2.5 / 2.5 (Confidence: 3 / 3 / 5)
Rebuttal might help, but outlook is dim.
-
1 / 2.5, confidence 5
Probably a confused or low-effort review.
-
OA 1 / 1 / 1
A review like this existed (likely invalid). Community flagged it.
 Additional comment from community
Additional comment from community- Some reviewers are still clearly junior-level, or appear to use AI tools for review generation.
- Findings threshold widely believed to be OA ≥ 2.5–3.0, assuming some confidence in reviews.
- Review score inflation is low this round: average OA above 3.0 is rare, even among decent papers.
- Several December and February round submissions are said to be evaluated independently due to evolving meta-review policies.
 ️ Summary
️ Summary- Score distributions reported in the Chinese community largely align with Reddit’s (see my previous post), which is 3.0 is the magic number for Findings, 3.5+ needed for Main.
- Rebuttal might swing things, but expectations are tempered.
- Many junior researchers are actively sharing scores to gauge chances and strategize next steps (rebut, withdraw, or resubmit elsewhere).
-
-
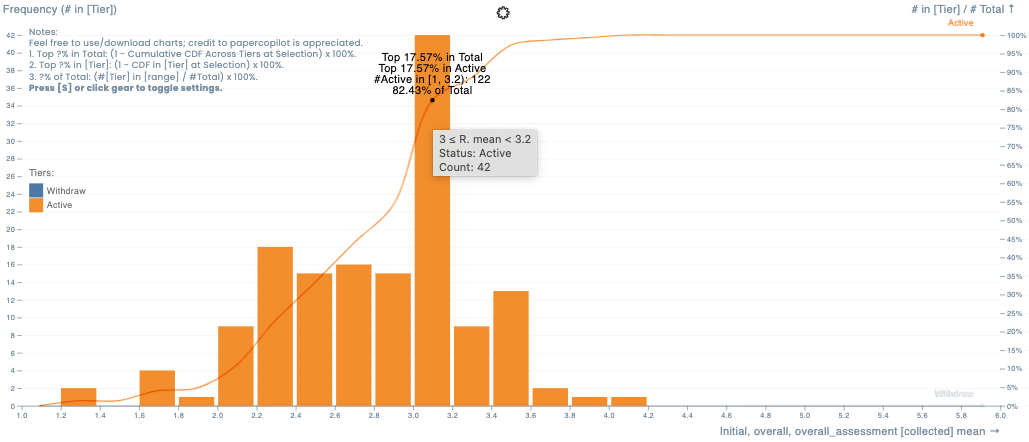
See here for a crowd-sourced score distribution (biased ofc): https://papercopilot.com/statistics/acl-statistics/acl-2025-statistics/
-
Got the ARR email — if your reviews came in late, are vague, low-effort, or seem AI-generated, you can now officially report them via OpenReview before April 7 (AOE). I think it’s worth flagging anything seriously wrong, since these reports influence both meta-review decisions and future review quality control. Details here: https://aclrollingreview.org/authors#step2.2
-
I honestly feel like one of my reviewers must’ve had their brain replaced by a potato. They gave my paper a 2 and listed some lukewarm, vague “weaknesses” that barely made sense. Meanwhile, I reviewed a paper that burned through over 200 H100s for a tiny performance gain.
I thought it lacked both cost-efficiency and novelty, and somehow they got a 4 from another reviewer? Seriously? That thing gets a 4, and mine, which is already deployed in real-world LLM production systems, resource-efficient and effective, gets a 2? I’m speechless.
Anyone know if it’s still viable to withdraw from Findings and submit to a journal instead? The work is pure NLP: Is TKDE still a good fit these days, or are there faster journals people would recommend?
Also… is this a trend now? Reviewers saying “Good rebuttal, I liked it,” but still not adjusting the score? What’s the point then? I spent so much time running extra experiments and carefully writing a detailed rebuttal, and it’s treated the same as if I’d done nothing. If this continues, maybe it’s time to just scrap the rebuttal phase altogether.

-
Got the ARR email — if your reviews came in late, are vague, low-effort, or seem AI-generated, you can now officially report them via OpenReview before April 7 (AOE). I think it’s worth flagging anything seriously wrong, since these reports influence both meta-review decisions and future review quality control. Details here: https://aclrollingreview.org/authors#step2.2
@root Totally agree!
Just to add: for top ML conferences like NeurIPS, ICML, and ICLR, it's also good practice to use the “confidential comments to AC” field when something seems off. That includes suspected plagiarism, conflicts of interest, or if you think a review is clearly low-effort or AI-generated but don’t want to make that accusation publicly. It helps ACs and PCs take appropriate action, and those comments are taken seriously during meta-review and future reviewer assignments.
-
Here are the historical acceptance rate of ACL conference:
Venue Long papers Short papers ACL'14 26.2% (146/572) 26.1% (139/551) ACL'15 25.0% (173/692) 22.4% (145/648) ACL'16 28.0% (231/825) 21.0% (97/463) ACL'17 25.0% (195/751) 18.9% (107/567) ACL'18 25.3% (258/1018) 24.0% (126/526) ACL'19 25.7% (447/1737) 18.2% (213/1168) ACL'20 25.4% (571/2244) 17.6% (208/1185) ACL'21 24.5% (571/2327) 13.6% (139/1023) ACL'21 Findings 14.6% (339/2327) 11.5% (118/1023) ACL'22 ? (604/?) ? (97/?) ACL'22 Findings ? (361/?) ? (361/?) ACL'23 23.5% (910/3872) 16.5% (164/992) ACL'23 Findings 18.4% (712/3872) 19.1% (189/992) -
The meta review has come out. I provide one data point:
Review scores: 2.5 2.5 2.5
Meta review 2.5Well ....
-
We also have one submission for ARR Feb. Hope it can be accepted as main conference at ACL 2025.
Review scores: 3, 3.5, 3.5
Meta review: 3.5