KDD 2025 2nd-round Review Results: How Did Your Paper Do?
-
Hey fellow KDD authors and ML researchers!


As we approach the release of the second-round review results for KDD 2025, it's time to gather, share experiences, and support each other: whether you're nervously checking for updates, celebrating a win, or figuring out your next steps.
🧩 What to Discuss Here:
- What scores did you get after Round 1 & rebuttal?
- Did your rebuttal help push your paper toward acceptance?
- Were you assigned to Research or ADS track?
- Are you seeing trends in novelty / technical quality (TQ) scores?
- What are your thoughts on this year's review quality?
 ️ Be cautious with rebuttals
️ Be cautious with rebuttalsSome authors reported issues with anonymous external code links (e.g., GitHub repos). Even if anonymized, external links in the rebuttal can trigger desk rejection depending on PC interpretation. If you’re unsure, it’s safest to:
- Clearly reference what's already in the submission
- Avoid linking out to anything not explicitly allowed
- Clarify any confusion in the rebuttal without adding new external content
 Community Polls & Stats
Community Polls & StatsSome have started collecting anonymized data points on scores and acceptance results; it's great to get a sense of where you stand. If you’ve got numbers (e.g.,
Novelty: 4 3 3 2,TQ: 3 2 3 2), feel free to drop them in the thread and compare notes!Let’s try to keep this thread constructive and supportive. Every score is a story, and every rejection can be a redirection.

 Looking Ahead
Looking AheadWhether you’re aiming to get into camera-ready or preparing a resubmission, this is the perfect moment to share, learn, and connect with others in the same boat.
Feel free to comment below with your situation, ask questions, or just vent — we’re here for it!
Stay strong, and good luck to everyone

— A fellow author + reviewer
-
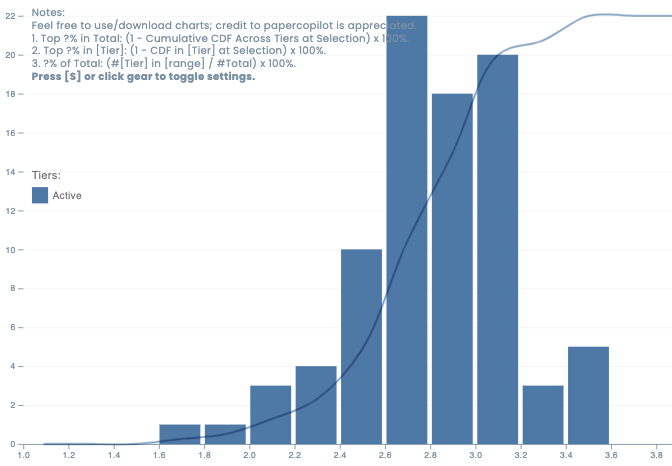
KDD reviews are coming out, and most community-shared scores cluster around 2.6 to 3.6 on average. Common patterns are like 333xx, 433xx, or 422xx, showing that many papers are seen as average in novelty and technical quality. Even submissions authors are proud of are mostly getting 3s, with only a few 4s or 5s. The overall vibe: “low scores are normal, let’s just hope for kind reviewers and make the most of rebuttal.”
In short, KDD remains tough, and scores are modest across the board.
-
A data point:
GNN work, got
Novelty: 3, 2, 2, 3, 2
Technical Quality: 2, 2, 2, 2, 2
Confidence: 3, 4, 3, 4, 4Need to rebuttal? anyone knows more? 2 weeks challenge ahead!
-
I made a comparison of KDD 2024 vs. KDD 2025 scoring/reviewing system. Here you go!
Scoring Dimensions and Their Scales
Scoring Dimension KDD 2024 KDD 2025 Change Relevance 1–4 1–4  No change
No changeNovelty 1–5 1–4  Reduced
ReducedTechnical Quality 1–5 1–4 ReducedPresentation Quality 1–5 1–4 ReducedReproducibility 1–5 1–4 ReducedReviewer Confidence 1–5 1–4 ReducedNote: The reduction from a 5-point to a 4-point scale compresses the neutral midpoint, encouraging reviewers to take a clearer stance on each dimension.
Review Form Structure Changes
Review Element KDD 2024 KDD 2025 Change Paper Summary, Strengths, Weaknesses Required (Free-form) Required (Free-form) No changeQuestions for Rebuttal Optional / General Required: Numbered, specific New requirementResubmission Flag  Not included "Resubmission" + "Repeat Reviewer" New
Not included "Resubmission" + "Repeat Reviewer" NewEthics Review Flag Yes / No Yes / No No changeLLM Usage Disclosure Not asked Mandatory New
Emphasis in KDD 2025
Rebuttal Process:
- Authors benefit from clearly numbered, targeted reviewer questions.
- Reviewers are expected to provide actionable feedback.
Transparency:
- Reviewers must disclose any use of Large Language Models (LLMs).
- Tracks resubmission history and reviewer continuity.
Reproducibility:
- Still emphasized, with refined grading from "insufficient" to "excellent" support materials.
A summary table
Area KDD 2024 KDD 2025 Key Difference Scoring Scale 1–5 (most categories) 1–4 (all categories)  ️ Compressed scale
️ Compressed scaleReview Structure Free-form + ratings Structured + specific queries More actionableRebuttal Support Optional Mandatory, numbered EnforcedLLM Disclosure Not applicable Required NewResubmission Tracking Not tracked Explicitly included New -
My reproducibility score hurt a lot because of my source code link does not work any more. I was using LimeWire + ShortURL. Real bad service!

Next time, I will use CSPaper!!
https://cspaper.org/category/10/anonymous-sharing-supplementary-materials
Here is an example:
https://cspaper.org/topic/38/kdd2025-2nd-tgn-adapted-anonymous-source-code-for-review-only
-
-
My reproducibility score hurt a lot because of my source code link does not work any more. I was using LimeWire + ShortURL. Real bad service!
Next time, I will use CSPaper!!
https://cspaper.org/category/10/anonymous-sharing-supplementary-materials
Here is an example:
https://cspaper.org/topic/38/kdd2025-2nd-tgn-adapted-anonymous-source-code-for-review-only
-
I made a summary of data points from KDD 2025 1st round results:
Novelty Scores Technical Quality Scores Confidence Scores Rebuttal Outcome Final Decision Notes 3 3 3 3 3 3 4 3 3 2 3 2 – Addressed issues Accepted"Rebuttal is so difficult with all the twists and turns" 2 2 3 2 2 3 3 2 2 3 3 3 3 3 3 Submitted Rejected"Can I just run away?" 4 3 3 1 4 4 2 2 – Explained issues Rejected"Large variance across reviewers; no score changes post-rebuttal" 3 3 3 3 3 2 – Unsure 🟡 Unknown "Still considering rebuttal; not sure if it's worth the effort" 3 3 3 3 3 3 3 3 3 3 3 2 – Minor clarifications Accepted"Final scores unchanged but accepted after positive AC decision" 3 4 3 3 3 3 2 2 3 2 2 3 – Clarified results Rejected"Novelty OK, but TQ too weak; didn't convince reviewers" 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Submitted Accepted"Strong consensus; one of the smoother cases" 3 3 3 3 3 2 – No rebuttal Rejected"No rebuttal submitted; borderline scores" 3 3 2 2 3 3 2 2 – Rebuttal sent Rejected"Reviewers did not change their opinion" 3 3 3 3 3 3 3 3 3 3 2 2 – Rebuttal helped Accepted"Accepted despite one weaker reviewer" 3 3 3 3 3 3 3 3 3 3 3 3 Rebuttal sent 🟡 Unknown "In limbo; waiting for final decision" 3 3 3 3 2 2 2 2 – Not convincing Rejected"Work deemed not ‘KDD-level’ despite rebuttal" 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Submitted Accepted"Perfectly consistent reviewers; smooth acceptance" 3 3 3 2 3 3 2 2 – Rebuttal failed Rejected"Low technical quality and variance led to rejection"  Note: Data sourced from community discussions on Zhihu, Reddit, and OpenReview threads. Subject to sample bias.
Note: Data sourced from community discussions on Zhihu, Reddit, and OpenReview threads. Subject to sample bias. -
A data point:
GNN work, got
Novelty: 3, 2, 2, 3, 2
Technical Quality: 2, 2, 2, 2, 2
Confidence: 3, 4, 3, 4, 4Need to rebuttal? anyone knows more? 2 weeks challenge ahead!
So sorry to hear that — sounds like a solid paper.
For my case,
One reviewer gave two 2s just because they didn’t see the value of improving efficiency or where it would be useful, even though that’s the whole point of many ML contributions. Another reviewer didn’t understand the paper and asked for line-by-line comments on pseudocode. That’s just disheartening.Also noticed each review response is limited to 2500 characters. Does anyone know if we can reply in multiple stacked comments?
-
https://www.zhihu.com/question/12035973262/answers/updated
some data points from Chinese researcher community -
Anyone knows the likelihood of an NLP (LLM agent and its evaluation on many public datasets) work accepted to KDD, either main or applied data science track?
-
what are the chances of acceptance in KDD feb, here is my score
Relevance: 3.5 (based on 4, 3, 4, 3, 4)
Novelty: 3.0 (based on 4, 3, 2, 3, 2)
Technical Quality: 3.0 (based on 3, 3, 3, 3, 3)
Presentation: 2.8 (based on 3, 3, 3, 2, 3)
Reproducibility: 3.0 (based on 3, 3, 3, 3, 3)
Reviewer Confidence: 3.4 (based on 3, 4, 3, 4, 3) -
what are the chances of acceptance in KDD feb, here is my score
Relevance: 3.5 (based on 4, 3, 4, 3, 4)
Novelty: 3.0 (based on 4, 3, 2, 3, 2)
Technical Quality: 3.0 (based on 3, 3, 3, 3, 3)
Presentation: 2.8 (based on 3, 3, 3, 2, 3)
Reproducibility: 3.0 (based on 3, 3, 3, 3, 3)
Reviewer Confidence: 3.4 (based on 3, 4, 3, 4, 3)@Nilesh-Verma from what I hear, Novelty and TQ (combined with confidence) are two most important dimension for making the final decision. I think TQ scores are pretty good; Novelty scores are not bad either. If rebuttal can increase one of the "2"s to 3, then the chance of getting an acceptance will be even higher.
-
I hereby paste the historical acceptance rate of KDD research tracks
Conference Long Paper Acceptance Rate KDD'14 14.6% (151/1036) KDD'15 19.5% (160/819) KDD'16 13.7% (142/1115) KDD'17 17.4% (130/748) KDD'18 18.4% (181/983) (107 orals and 74 posters) KDD'19 14.2% (170/1200) (110 orals and 60 posters) KDD'20 16.9% (216/1279) KDD'22 15.0% (254/1695) KDD'23 22.1% (313/1416) KDD'24 20.0% (411/2046) Note that KDD'24 accepted 151 ADS track papers from 738 submissions!
-
The KDD PC just opened the comment phase until Apr 18 (AoE). You can respond to reviewer follow-ups or raise concerns to AC/SAC via the Official Comment button.
️ A few don’ts:- No URLs — they’ll auto-delete your comment.
- No bypassing rebuttal limits — don’t treat comments as extra rebuttal space.
- Don’t badger reviewers — 1 ping is enough.
- Stay respectful — tone matters.
Good luck everyone
-
I made a summary of data points from KDD 2025 1st round results:
Novelty Scores Technical Quality Scores Confidence Scores Rebuttal Outcome Final Decision Notes 3 3 3 3 3 3 4 3 3 2 3 2 – Addressed issues Accepted"Rebuttal is so difficult with all the twists and turns" 2 2 3 2 2 3 3 2 2 3 3 3 3 3 3 Submitted Rejected"Can I just run away?" 4 3 3 1 4 4 2 2 – Explained issues Rejected"Large variance across reviewers; no score changes post-rebuttal" 3 3 3 3 3 2 – Unsure 🟡 Unknown "Still considering rebuttal; not sure if it's worth the effort" 3 3 3 3 3 3 3 3 3 3 3 2 – Minor clarifications Accepted"Final scores unchanged but accepted after positive AC decision" 3 4 3 3 3 3 2 2 3 2 2 3 – Clarified results Rejected"Novelty OK, but TQ too weak; didn't convince reviewers" 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Submitted Accepted"Strong consensus; one of the smoother cases" 3 3 3 3 3 2 – No rebuttal Rejected"No rebuttal submitted; borderline scores" 3 3 2 2 3 3 2 2 – Rebuttal sent Rejected"Reviewers did not change their opinion" 3 3 3 3 3 3 3 3 3 3 2 2 – Rebuttal helped Accepted"Accepted despite one weaker reviewer" 3 3 3 3 3 3 3 3 3 3 3 3 Rebuttal sent 🟡 Unknown "In limbo; waiting for final decision" 3 3 3 3 2 2 2 2 – Not convincing Rejected"Work deemed not ‘KDD-level’ despite rebuttal" 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Submitted Accepted"Perfectly consistent reviewers; smooth acceptance" 3 3 3 2 3 3 2 2 – Rebuttal failed Rejected"Low technical quality and variance led to rejection" Note: Data sourced from community discussions on Zhihu, Reddit, and OpenReview threads. Subject to sample bias. -
what are the chances of acceptance in KDD feb, here is my score
Relevance: 3.5 (based on 4, 3, 4, 3, 4)
Novelty: 3.0 (based on 4, 3, 2, 3, 2)
Technical Quality: 3.0 (based on 3, 3, 3, 3, 3)
Presentation: 2.8 (based on 3, 3, 3, 2, 3)
Reproducibility: 3.0 (based on 3, 3, 3, 3, 3)
Reviewer Confidence: 3.4 (based on 3, 4, 3, 4, 3)@Nilesh-Verma Hi Nilesh, I am sure the scores of your paper are higher than those of most authors. Congs. Besides, did your reviewers increase their ratings for your paper in the rebuttal process?
-
@river Hi river,
Excuse me, do you know if these scores are the final scores after the rebuttal? Really appreciate it if you could provide more information about this
")
This the best effort scores, meaning I take the latest available scores reported in the community. If they are updated by the authors after rebuttal, then I take that, otherwise I would assume the scores did not change.
For the data points with accept/reject outcome, I think all of them are post-rebuttal scores.
-
A data point:
GNN work, got
Novelty: 3, 2, 2, 3, 2
Technical Quality: 2, 2, 2, 2, 2
Confidence: 3, 4, 3, 4, 4Need to rebuttal? anyone knows more? 2 weeks challenge ahead!
Hi magicparrots!
did the reviewers raise their scores for your paper after the rebuttal process?
I also submitted a paper about GNN, and only one reviewer out of five raised 1 score for my paper
-
This the best effort scores, meaning I take the latest available scores reported in the community. If they are updated by the authors after rebuttal, then I take that, otherwise I would assume the scores did not change.
For the data points with accept/reject outcome, I think all of them are post-rebuttal scores.
@river Many thanks for your details!