A Theory in Flux Yet Still Legendary—Why BatchNorm Took Home the ICML 2025 Test-of-Time Award
-

Since its debut in 2015, Batch Normalization (BN) has seen its original motivation repeatedly “debunked” by follow-up work, yet in 2025 it still captured the ICML Test-of-Time prize to Sergey Ioffe and Christian Szegedy.

What does that really say? This article traces BN’s canonisation by following two threads: the award’s evaluation logic and the layer’s systemic impact on deep learning.
1. The Test-of-Time award is not about being theoretically perfect
The ICML guidelines are explicit: the Test-of-Time award honours papers published ten years ago that shaped the field in the decade since. It does not reaudit theoretical soundness.
- Impact metrics: the BN paper has been cited more than 60 000 times, making it one of the most-cited deep-learning papers of its era.
- Down stream work: from regularisation and optimisation to architecture design, hundreds of papers start from BN to propose improvements or explanations.
- Practical penetration: BN is baked into almost every mainstream DL framework’s default templates, becoming a “no-brainer” layer for developers.
Conclusion: What the committee weighs is: “If you removed this paper ten years later, would the community be missing a cornerstone?” Theoretical controversy does not diminish its proven engineering value.
2. So what is the theory behind BatchNorm?
The original motivation was to reduce Internal Covariate Shift (ICS): as parameters change, the input distribution of downstream layers drifts, forcing them to continually adapt, slowing and destabilising training. BN standardises activations within each mini-batch, explicitly anchoring the distribution and decoupling layers.
Two-step recipe
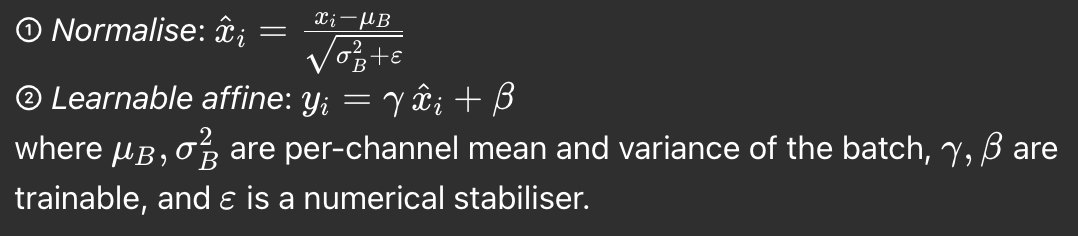
Key derivations
- Normalisation → stable gradients: zero-mean/unit-variance keeps activations in “flat” regions of nonlinearities, mitigating exploding/vanishing gradients.
- Affine → full expressiveness: adding ( \gamma, \beta ) re-parameterises rather than constrains the network.
- Train vs. inference: batch statistics at train time; running averages for deterministic inference.
Theoretical evolution
Later studies (e.g. Santurkar 2018; Balestriero 2022) argue that ICS is not the sole driver. They instead find that BN smooths the loss landscape and improves gradient predictability, or acts as an adaptive, unsupervised initialisation, still analysing why the two-step recipe works.
3. Each challenge to the theory has reinforced its hard value
Year Key objection Outcome & new view 2018 (MIT) Injecting noise after BN shows “ICS is not essential”; the real benefit is a smoother optimisation landscape & more predictable gradients. Training still accelerates  ︎ → BN framed as an “optimiser accelerator”.
︎ → BN framed as an “optimiser accelerator”.2022 (Rice & Meta) Geometric view: BN resembles an unsupervised adaptive initialiser and, via mini-batch noise, enlarges decision-boundary margins. Explains BN’s persistent generalisation boost.
4. Five cascading effects on the deep-learning stack
1). Unlocked ultra deep training
ResNet and its descendants scaled from tens to hundreds or even thousands of layers largely because a BN layer can be slotted into every residual block.
2). Halved (or better) training time & compute
In its release year BN slashed ImageNet SOTA training steps to 1⁄14, directly pushing large-scale adoption in industry.
3). Normalised high learning rates / weak initialisation
Tedious hand-tuning became optional, freeing AutoML and massive hyper-parameter sweeps.
4). Spawned the “Norm family”
LayerNorm, GroupNorm, RMSNorm… each targets a niche but all descend from BN’s interface and analysis template.
5). Reshaped optimisation theory
BN-inspired ideas like “landscape smoothing” and “re-parameterisation” rank among the most-cited optimisation topics in recent years.
5. Why systemic impact outweighs a perfect theory
- Industrial priority: The top question is whether a technique lifts stability / speed / cost, BN does.
- Scholarly spill-over: Even evolving explanations are fertile academic fuel once the phenomena are reproducible.
- Ecosystem lock in: Once written into framework templates, textbooks and inference ASIC kernels, replacement costs skyrocket, creating a de-facto standard.
One-sentence summary: Like TCP/IP, even if first generation assumptions later prove flawed, BN remains the “base protocol” of the deep-learning era.
6. Looking ahead
- Open question: Micro batch training and self-attention violate BN’s statistical assumptions, will that spark a next gen normalisation?
- Methodology: BN’s success hints that intuition + engineering validation can drag an entire field forward faster than a closed-form theory.
- Award lesson: The Test-of-Time prize reminds us that long-term influence ≠ flawless theory; it’s about leaving behind reusable, recombinable “public Lego bricks”.
Recommended reading
- Sergey Ioffe & Christian Szegedy, Batch Normalization (2015)
- Shibani Santurkar et al., How Does Batch Normalization Help Optimisation? (2018)
- Randall Balestriero & Richard Baraniuk, Batch Normalization Explained (2022)