So, this is the so called reward hacking 

Global Moderators
Forum wide moderators
Private
Posts
-
😈 The ICML Auto-Acknowledge Cycle: A Dark Satire -
KDD 2025 2nd-round Review Results: How Did Your Paper Do?I made a summary of data points from KDD 2025 1st round results:
Novelty Scores Technical Quality Scores Confidence Scores Rebuttal Outcome Final Decision Notes 3 3 3 3 3 3 4 3 3 2 3 2 – Addressed issues  Accepted
Accepted"Rebuttal 一波三折太难了" 2 2 3 2 2 3 3 2 2 3 3 3 3 3 3 Submitted  Rejected
Rejected"是不是可以直接跑路了" 4 3 3 1 4 4 2 2 – Explained issues Rejected"Large variance across reviewers; no score changes post-rebuttal" 3 3 3 3 3 2 – Unsure 🟡 Unknown "Still considering rebuttal; not sure if it's worth the effort" 3 3 3 3 3 3 3 3 3 3 3 2 – Minor clarifications Accepted"Final scores unchanged but accepted after positive AC decision" 3 4 3 3 3 3 2 2 3 2 2 3 – Clarified results Rejected"Novelty OK, but TQ too weak; didn't convince reviewers" 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Submitted Accepted"Strong consensus; one of the smoother cases" 3 3 3 3 3 2 – No rebuttal Rejected"No rebuttal submitted; borderline scores" 3 3 2 2 3 3 2 2 – Rebuttal sent Rejected"Reviewers did not change their opinion" 3 3 3 3 3 3 3 3 3 3 2 2 – Rebuttal helped Accepted"Accepted despite one weaker reviewer" 3 3 3 3 3 3 3 3 3 3 3 3 Rebuttal sent 🟡 Unknown "In limbo; waiting for final decision" 3 3 3 3 2 2 2 2 – Not convincing Rejected"Work deemed not ‘KDD-level’ despite rebuttal" 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Submitted Accepted"Perfectly consistent reviewers; smooth acceptance" 3 3 3 2 3 3 2 2 – Rebuttal failed Rejected"Low technical quality and variance led to rejection"  Note: Data sourced from community discussions on Zhihu, Reddit, and OpenReview threads. Subject to sample bias.
Note: Data sourced from community discussions on Zhihu, Reddit, and OpenReview threads. Subject to sample bias. -
KDD 2025 2nd-round Review Results: How Did Your Paper Do? -
KDD 2025 2nd-round Review Results: How Did Your Paper Do? -
🎪 ACL 2025 Reviews Are Out: To Rebut or Flee? The Harsh Reality of NLP’s "Publish or Perish" CircusThe Verdict: ACL 2025 Review Scores Decoded
This year’s Overall Assessment (OA) descriptions reveal a brutal hierarchy:
 5.0 "Award-worthy (top 2.5%)"
5.0 "Award-worthy (top 2.5%)" ️ 4.0 "ACL-worthy"
️ 4.0 "ACL-worthy" 3.5 "Borderline Conference"
3.5 "Borderline Conference" 3.0 "Findings-tier" (Translation: "We’ll take it… but hide it in the appendix")
3.0 "Findings-tier" (Translation: "We’ll take it… but hide it in the appendix") 1.0 "Do not resubmit" (a.k.a. "Burn this and start over")
1.0 "Do not resubmit" (a.k.a. "Burn this and start over")
Pro tip: A 3.5+ OA avg likely means main conference; 3.0+ scraps into Findings. Meta-reviewers now hold life-or-death power—one 4.0 can save a 3.0 from oblivion.
Nightmare Fuel: The 6-Reviewer Special
"Some papers got 6 reviewers—likely because emergency reviewers were drafted last-minute. Imagine rebutting 6 conflicting opinions… while praying the meta-reviewer actually reads your response."
Rebuttal strategy:
- 2.0? "Give up." (Odds of salvation: ~0%)
- 2.5? "Worth a shot."
- 3.0? "Fight like hell."
The ARR Meat Grinder Just Got Worse
New changes to the ARR (Academic Rebuttal Rumble):
 5 cycles/year now (April’s cycle vanished; June moved to May).
5 cycles/year now (April’s cycle vanished; June moved to May).- EMNLP’s deadline looms closer — less time to pivot after ACL rejections.
 LLM stampede: *"8,000+ submissions per ARR cycle!
LLM stampede: *"8,000+ submissions per ARR cycle!
"Back in the days, ACL had 3,000 submissions. No Findings, no ARR, no LLM hype-train. Now it’s just a content farm with peer review."
How to Survive the Madness
 Got a 3.0? Pray your meta-reviewer is merciful.
Got a 3.0? Pray your meta-reviewer is merciful.- 🤬 Toxic review? File an "issue" (but expect crickets).
 ARR loophole: "Score low in Feb? Resubmit to May ARR and aim for EMNLP."
ARR loophole: "Score low in Feb? Resubmit to May ARR and aim for EMNLP."
The Big Picture: NLP’s Broken Incentives
- Reviewer fatigue: Emergency reviewers = rushed, clueless feedback.
- LLM monoculture: 90% of papers are "We scaled it bigger" or "Here’s a new benchmark for our 0.2% SOTA."
- Findings graveyard: Where "technically sound but unsexy" papers go to die.
Final thought: "If you’re not gaming the system, the system is gaming you."
Adapted from JOJO极智算法 (2025-03-28)
 Share your ACL 2025 horror stories below! Did you rebut or run?
Share your ACL 2025 horror stories below! Did you rebut or run? -
ICLR'25 and ICML'24 Papers Are Strikingly Similar! Netizens Are FuriousOriginally posted by Zhihu user “灰瞳六分仪” (Huítóng Liùfēnyí) on: March 28, 2025, 16:47
I’d like to point out a paper that I found rather disturbing — I noticed that the ICLR 2025 paper Mixture of Attentions (MoA) is strikingly similar to the ICML 2024 paper GliDe. Let’s first drop the links to both papers:
MoA: https://openreview.net/pdf?id=Rz0kozh3LE
GliDe: https://openreview.net/pdf?id=mk8oRhox2I
To be honest, I initially had no intention of bringing this to Zhihu — after all, allegations of potential academic misconduct are very serious. So I first posted a public comment on OpenReview, politely asking the authors for clarification. But the author’s response and the excuse made in the camera-ready version really infuriated me. So now I’m going to break this down properly.
The Excuse That Made Me Mad
Let’s look at how the authors themselves explained the difference between MoA and GliDe in the camera-ready version:
Du et al. (2024) previously proposed to leverage the KV-cache of some layers of 𝓜_{large}. They do not justify why using the KV-cache instead of the output of each layer, nor how to exactly choose which layer to include as input of 𝓜_{small} However, with our dynamical system point of view, we showed that the KV-cache of all the layers is part of the state. The introduction of LSA allows to exploit it in its whole with a limited number of layers, whereas Du et al. (2024) would need to have the same number of layers in 𝓜_{small} and 𝓜_{large} to fully capture it, resulting in a slow drafting speed.
This explanation claims a “lack of justification” from Du et al. (2024), but…
This Is Just Wrong.
GliDe only used the last layer’s KV cache — and explicitly ran ablation studies to justify this. Check Figure 7 of the GliDe paper if you don’t believe me.
Such a misleading statement raises the question: Were MoA’s authors intentionally trying to confuse readers and obscure the similarity between the two works?
A Side-by-Side Comparison of Core Methods
Let me help the MoA authors do a better comparison between GliDe and MoA. Below are the main method diagrams from both papers:
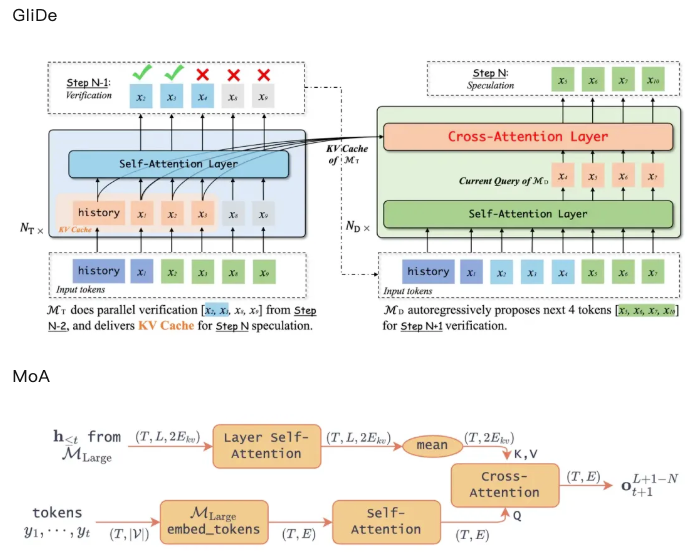
So yeah, the core frameworks are nearly identical. If we’re nitpicking, the difference is:
- GliDe uses only the last layer’s KV cache
- MoA takes the average across all layers’ KV cache
I’ve summarized this comparison in the table below.
Method GliDe (ICML 2024) MoA (ICLR 2025) Core Process Pass input through the target model (large model)'s embedding layer, then generate query via self-attention, and finally compute cross-attention with the target model's KV cache Same as GliDe: embedding → self-attention → compute cross-attention with KV cache from the target model Use of Target Model's KV Cache Only uses the last layer of the target model's KV cache Uses the entire KV cache from all layers of the target model Draft Model Layers 1 layer for 7B/13B models, 2 layers for 33B model 1 layer Citation Issues in MoA: Avoiding GliDe on Purpose?
Despite the similarity, the initial draft of MoA didn’t cite GliDe at all!
 This likely caused the four reviewers and AC to miss the similarity in methodology — which probably explains why MoA scored so highly (6,6,8,8).
This likely caused the four reviewers and AC to miss the similarity in methodology — which probably explains why MoA scored so highly (6,6,8,8).Academic ethics require properly citing related work, especially if the work is highly similar. I’m not going to declare this academic misconduct, but I do believe the authors benefited from this omission.
Side Note: Why Did GliDe Perform Worse Than EAGLE, But MoA Didn't?
I figured this out while working on LongSpec. In my view, GliDe actually has high potential, because the information in hidden states should also exist in the KV cache. I wrote in a previous reading note:
“This paper shares the same idea as EAGLE — both reuse the target model’s knowledge of the prompt. The only difference is: this paper uses the KV cache, while EAGLE uses hidden states. Logically, KV cache should be slightly better.”
According to experts at together.ai, their reproduction results also show that MoA performs slightly better.
So why did GliDe underperform in its paper?
- The original GliDe code had quite a few bugs
 .
. - During MT-Bench evaluation, GliDe only evaluated the first turn — discarding subsequent prompts. The later turns, usually involving error correction, should have contributed significantly to accept rate.
So honestly, the main contribution of MoA is just getting GliDe to work properly.
Conclusion
Based on the above analysis, here’s my personal opinion:
- The core methods of MoA and GliDe are highly similar — with little innovation — this is essentially a duplicate.
- MoA’s authors misrepresented GliDe’s method in their camera-ready version to create the illusion of difference.
- MoA’s draft did not cite GliDe, possibly intentionally — which violates academic norms.
Regrettably, I didn’t discover this paper during the discussion phase, so I missed the opportunity to raise it with reviewers. I later submitted a report to the ICLR program committee — but it went nowhere. In the end, MoA was still accepted to ICLR 2025.

What do you think — does this count as academic misconduct?
-
🔥 ICML 2025 Review Results are Coming! Fair or a Total Disaster? 🤯ICML — also known as I Cannot Manage Life. The world’s most famous reviewer torture conference, held annually. You submit one paper, review five. Doesn’t matter if it’s not your area — you’ll have to figure it out anyway. Comments need to be detailed, long, and exhaustive. Finishing one review basically feels like writing half a paper. No money for reviews, just dedicating all your pure love. And after all those late-night comments? Guess what — the AC might not even consider them, and even a paper with all-positive reviews can still get rejected.
-
🔥 ICML 2025 Review Results are Coming! Fair or a Total Disaster? 🤯 -
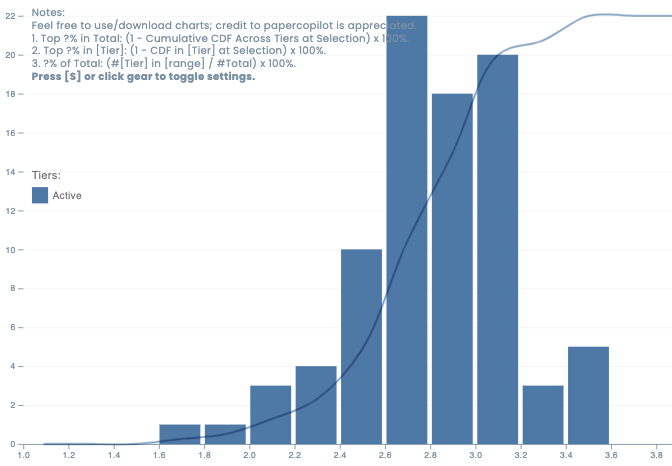
🔥 ICML 2025 Review Results are Coming! Fair or a Total Disaster? 🤯Here is a crowed sourced score distribution for this year:
https://papercopilot.com/statistics/icml-statistics/icml-2025-statistics/And, you can also refer to the previous year's score distributions in relation to accept/reject:
https://papercopilot.com/statistics/icml-statistics/
-
Early ICME 2025 Decision Exposed? fix needed 🛠️Recently, someone surfaced (again) a method to query the decision status of a paper submission before the official release for ICME 2025. By sending requests to a specific API (
https://cmt3.research.microsoft.com/api/odata/ICME2025/Submissions(Your_paper_id)) endpoint in the CMT system, one can see the submission status via a StatusId field, where1means pending,2indicates acceptance, and3indicates rejection.This trick is not limited to ICME 2025. It appears that the same method can be applied to several other conferences, including: IJCAI, ICME, ICASSP, IJCNN and ICMR.
However, it is important to emphasize that using this technique violates the fairness and integrity of the peer-review process. Exploiting such a loophole undermines the confidentiality and impartiality that are essential to academic evaluations. This is a potential breach of academic ethics, and an official fix is needed to prevent abuse.
Below is a simplified Python script that demonstrates how this status monitoring might work. Warning: This code is provided solely for educational purposes to illustrate the vulnerability. It should not be used to bypass proper review procedures.
import requests import time import smtplib from email.mime.text import MIMEText from email.header import Header import logging # Configure logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler("submission_monitor.log"), logging.StreamHandler() ] ) # List of submission URLs to monitor (replace 'Your_paper_id' accordingly) SUBMISSION_URLS = [ "https://cmt3.research.microsoft.com/api/odata/ICME2025/Submissions(Your_paper_id)", "https://cmt3.research.microsoft.com/api/odata/ICME2025/Submissions(Your_paper_id)" ] # Email configuration (replace with your actual details) EMAIL_CONFIG = { "smtp_server": "smtp.qq.com", "smtp_port": 587, "sender": "your_email@example.com", "password": "your_email_password", "receiver": "recipient@example.com" } def get_status(url): """ Check the submission status from the provided URL. Returns the status ID and a success flag. """ try: headers = { 'User-Agent': 'Mozilla/5.0', 'Accept': 'application/json', 'Referer': 'https://cmt3.research.microsoft.com/ICME2025/', # Insert your cookie here after logging in to CMT 'Cookie': 'your_full_cookie' } response = requests.get(url, headers=headers, timeout=30) if response.status_code == 200: data = response.json() status_id = data.get("StatusId") logging.info(f"URL: {url}, StatusId: {status_id}") return status_id, True else: logging.error(f"Failed request. Status code: {response.status_code} for URL: {url}") return None, False except Exception as e: logging.error(f"Error while checking status for URL: {url} - {e}") return None, False def send_notification(subject, message): """ Send an email notification with the provided subject and message. """ try: msg = MIMEText(message, 'plain', 'utf-8') msg['Subject'] = Header(subject, 'utf-8') msg['From'] = EMAIL_CONFIG["sender"] msg['To'] = EMAIL_CONFIG["receiver"] server = smtplib.SMTP(EMAIL_CONFIG["smtp_server"], EMAIL_CONFIG["smtp_port"]) server.starttls() server.login(EMAIL_CONFIG["sender"], EMAIL_CONFIG["password"]) server.sendmail(EMAIL_CONFIG["sender"], [EMAIL_CONFIG["receiver"]], msg.as_string()) server.quit() logging.info(f"Email sent successfully: {subject}") return True except Exception as e: logging.error(f"Failed to send email: {e}") return False def monitor_submissions(): """ Monitor the status of submissions continuously. """ notified = set() logging.info("Starting submission monitoring...") while True: for url in SUBMISSION_URLS: if url in notified: continue status, success = get_status(url) if success and status is not None and status != 1: email_subject = f"Submission Update: {url}" email_message = f"New StatusId: {status}" if send_notification(email_subject, email_message): notified.add(url) logging.info(f"Notification sent for URL: {url} with StatusId: {status}") if all(url in notified for url in SUBMISSION_URLS): logging.info("All submission statuses updated. Ending monitoring.") break time.sleep(60) # Wait for 60 seconds before checking again if __name__ == "__main__": monitor_submissions()
Parting thoughts
While the discovery of this loophole may seem like an ingenious workaround, it is fundamentally unethical and a clear violation of the fairness expected in academic peer review. Exploiting such vulnerabilities not only compromises the integrity of the review process but also undermines the trust in scholarly communications.
We recommend the CMT system administrators to implement an official fix to close this gap. The academic community should prioritize fairness and the preservation of rigorous, unbiased review standards over any short-term gains that might come from exploiting such flaws.